In our latest article we explored an optimized approach for Preloading data using Redis and Kafka Connectors, particular for real time applications that need fast, efficient data access. We demonstrate how redis can serve as an effective alternative to traditional ODS layers, reducing database load and providing enhanced data retrieval speed.
In this article will introduce kafka stream for producing and processing real time data .
Introduction to Real-Time Data Processing
Real-time Streaming refers to quickly processing data, A continuous data stream is processed as received and outcomes are stored for review or record.Rail time processing differs from batch processing , which ingests and retains data to be reviewed at a later time or data.
Real time data processing enable data Owners/Business to interpret data on demand and make decisions accordingly. this approach also eliminates the need to store large data,since the data is processed continuously in a real time.
Use Case Scenario: Average Customer Spending Calculation
We will continue from our latest use case Scenario where we aggregate our customer profile, accounts and latest transactions, we will add important information to our customer that will enable them to understand spending patterns, By calculating the average customer spending in real time,this will help our customers manage their finances better.
In this scenario we will use Kafka steam to continuously process transaction data , calculate the average spending and store the results in Redis for fast retrieval.
Our Architecture will leverage Kafka stream to compute average spending per customer by aggregating their transaction data in real time. The processed data will be stored in Redis, where it can be accessed by our microservice that retrieves and display this information.
Kafka Stream
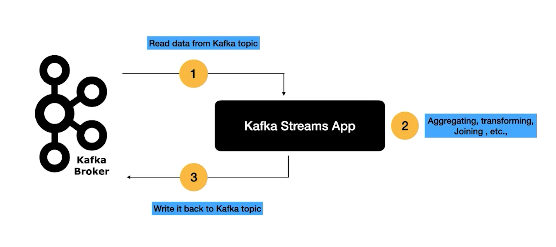
Kafka Streams is a Java library that we use to write stream processing applications. It’s a standalone app that streams records to and from Kafka.
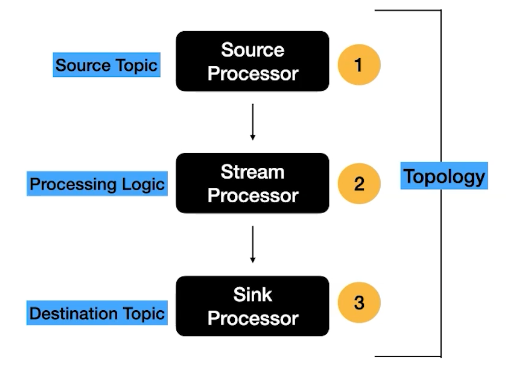
The core of a Kafka stream application is its topology, which defines how data flows through various processing nodes. A topology is a directed graph of stream processors (nodes) and streams (edges).
Kafka stream application has a series of processes :
-
Source processor that read data from source topic or topics
-
Stream processor where we have the processing Logic which is responsible for acting on the data from source processor(kafka topic) this could be aggregation , transforming or joining the data this is where the data enrichment happens.
-
Sink processor where the processed data returned to output kafka topic.
This collection of processors together forms the Topology.
Use Case Implementation
in order to implement our use case we need to follow the following steps :
-
Step 1: Create Kafka Steam App
-
Step 2: Create Redis Sink Connector
-
Step 3: Update Microservice to Read data from Redis
Step 1: Create Kafka Steam App
As we discussed kafka stream is a java library which primary focuses on :
-
Data Enrichment
-
Transformation of data
-
Aggregation of data
-
Joining data from multiple kafka topics
Kafka Stream API uses Functional Programming Style.
-
Kafka Stream App initiate the stream processing by subscripting to kafka topic.
-
Act on data from kafka topic by applying operation like Aggregation , transforming and joining data etc…
-
Once a processing completes wire the data back to kafka topic.
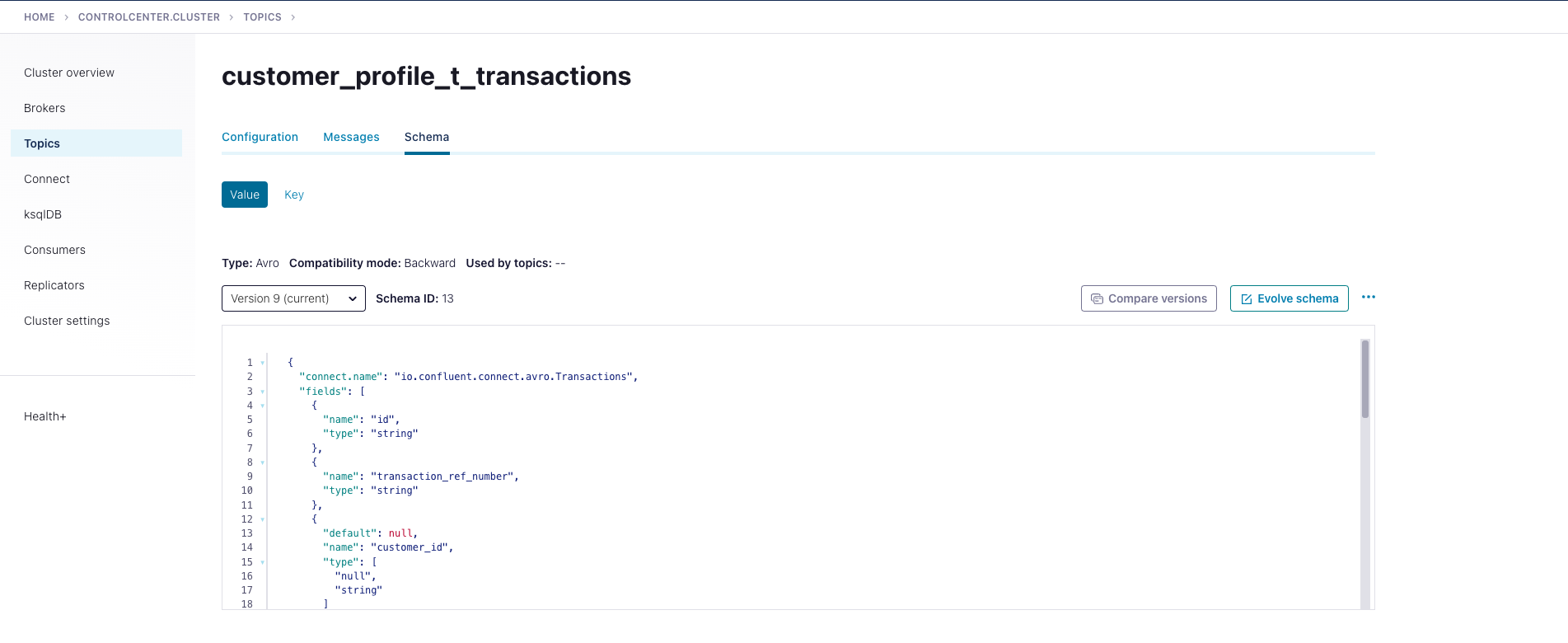
When we create the Kafka JDBC source connector to read from transaction table the connector created the topic and use avro schema to make publish the data to kafka topic, as shown below :
Avro is an open source data serialization system that helps with data exchange between systems, programming languages, and processing frameworks. Avro helps define a binary format for your data, as well as map it to the programming language of your choice.
For our stream app to start consuming the messages from transaction topic we need to deserialize the messages and map it to POJO this can be easily done by the following steps :
-
Download the Avro Schema and add it to the resource folder
-
Use Maven Aro plugin to read the schema and generate POJO class
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.12.0</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/avro/</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources</outputDirectory>
<stringType>String</stringType>
<fieldVisibility>PRIVATE</fieldVisibility>
</configuration>
</execution>
</executions>
</plugin>So now our complete maven dependency will be as following :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.motaz</groupId>
<artifactId>transaction-stream</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>transaction-stream</name>
<description>transaction-stream</description>
<properties>
<java.version>21</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.2</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>7.7.1</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-streams-avro-serde</artifactId>
<version>7.7.1</version>
</dependency>
</dependencies>
<repositories>
<!-- other maven repositories the project -->
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.12.0</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/avro/</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources</outputDirectory>
<stringType>String</stringType>
<fieldVisibility>PRIVATE</fieldVisibility>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Let’s use application.yml to provide the Kafka configuration:
spring:
application:
name: transaction-stream
kafka:
streams:
bootstrap-servers: PLAINTEXT_HOST://localhost:9092
application-id: transaction-streams-app
properties:
schema.registry.url: "http://localhost:8081"In our example, we’ve provided the application id and bootstrap server connection details for our configuration.
let’s define the Kafka stream configuration
@SpringBootApplication
@EnableKafka
@EnableKafkaStreams
public class TransactionStreamApplication {
public static void main(String[] args) {
SpringApplication.run(TransactionStreamApplication.class, args);
}
}Here, we’ve used the @EnableKafkaStreams annotation to autoconfigure the required components. As a result, Spring Boot uses this configuration and creates a KafkaStreams client to manage our application lifecycle
Now that we’ve set up the configuration, let’s build the topology for our application:
@Slf4j
@Component
public class AverageTransactionTopology {
@Value("${spring.kafka.topics.transaction_topic}")
private String TRANSACTION_TOPIC;
@Value("${spring.kafka.topics.average-spending_topic}")
private String TRANSACTION_AVERAGE_SPENDING_TOPIC;
@Value("${spring.kafka.properties.schema.registry.url}")
private String SCHEMA_REGISTRY_URL;
// Source stream from the topic
@Autowired
public void process(StreamsBuilder streamsBuilder){
//create serde for Serialization and Deserialization
Serde<String> stringSerde = Serdes.String();
Serde<AverageSpending> averageSpendingSerde = new JsonSerde<>(AverageSpending.class);
Serde<Transactions> transactionSerde = createTransactionAvroSerde(SCHEMA_REGISTRY_URL);
KStream<String,Transactions> transactionStream = streamsBuilder.stream(TRANSACTION_TOPIC,
Consumed.with(stringSerde,transactionSerde)
);
transactionStream
.print(Printed.<String,Transactions>toSysOut().withLabel("transactions"));
// Group by customerId, then aggregate
KTable<String, AverageSpending> averageSpendingTable = transactionStream
.filter((key,transaction)->isCreditTransaction(transaction))
.groupBy((key, transaction) -> transaction.getCustomerId(), Grouped.with(stringSerde, transactionSerde))
.aggregate(
AverageSpending::new,
(customerId, transaction, agg) -> updateAverageSpending(customerId, transaction, agg),
Materialized.with(stringSerde, averageSpendingSerde)
);
//Convert to Stream
KStream<String, AverageSpending> averageSpendingStream =
averageSpendingTable.toStream();
//print stream
averageSpendingStream
.print(Printed.<String, AverageSpending>toSysOut().withLabel("averageSpending"));
// Write the aggregation results back to a new topic
averageSpendingStream.to(TRANSACTION_AVERAGE_SPENDING_TOPIC,
Produced.with(stringSerde, averageSpendingSerde));
// Build and print the topology
Topology topology = streamsBuilder.build();
log.info("Kafka Streams Topology:\n{}", topology.describe());
}
private Serde<Transactions> createTransactionAvroSerde(String schemaRegistryUrl) {
Serde<Transactions> serde = new SpecificAvroSerde<>();
Map<String, String> config = new HashMap<>();
config.put("schema.registry.url", schemaRegistryUrl);
serde.configure(config, false); // 'false' for value (true for key)
return serde;
}
private boolean isCreditTransaction(Transactions transaction) {
return transaction != null
&& transaction.getTransactionAmount() != null
&& transaction.getCustomerId() != null
&&"Credit".equalsIgnoreCase(transaction.getTransactionType());
}
private AverageSpending updateAverageSpending(String customerId, Transactions transaction, AverageSpending averageSpending) {
averageSpending.setCustomerId(customerId);
averageSpending.setTotalAmount(averageSpending.getTotalAmount() + Double.valueOf(transaction.getTransactionAmount()));
averageSpending.setTransactionCount(averageSpending.getTransactionCount() + 1);
return averageSpending;
}
}Here, we’ve defined a configuration method and annotated it with @Autowired. Spring processes this annotation and wires a matching bean from the container into the StreamsBuilder argument.
StreamsBuilder gives us access to all the Kafka Streams APIs, and it becomes like a regular Kafka Streams application. In our example, we’ve used this high-level DSL to define the transformations for our application:
Create a KStream from the input topic using the specified key and value SerDes.
Create a KTable by grouping by customer Id’s and the aggregating the data.
Materialize the result and convert the KTable to stream (KStream<String, AverageSpending> averageSpendingStream), and write the aggregated result back to our output kafka topic (average-spending)
In essence, Spring Boot provides a very thin wrapper around Streams API while managing the lifecycle of our KStream instance. It creates and configures the required components for the topology and executes our Streams application. Importantly, this lets us focus on our core business logic while Spring manages the lifecycle.
We have printed our topology, and it can be visualized by using kafka-streams-viz
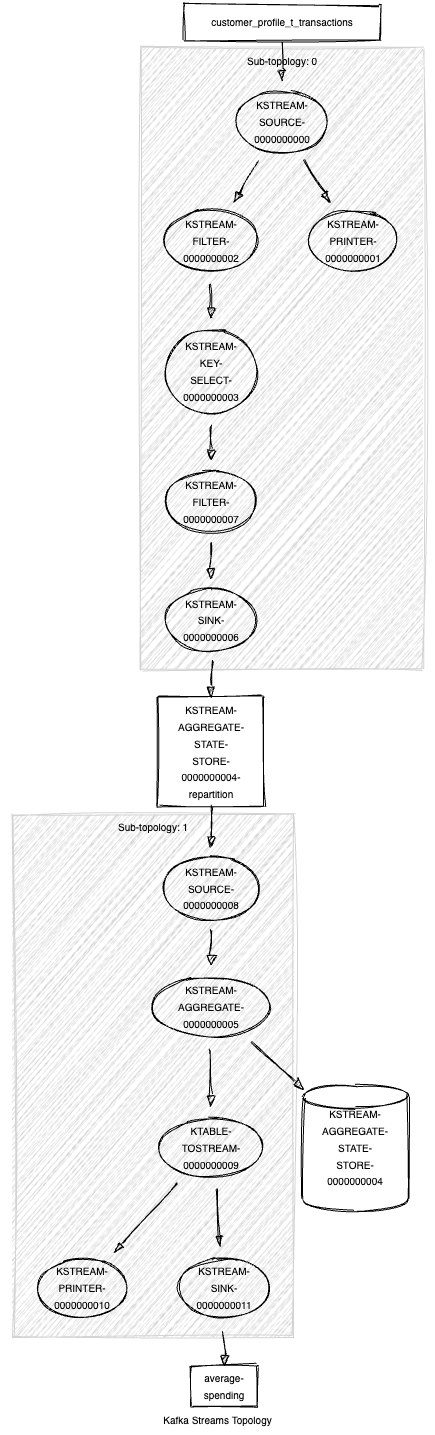
The visualized topology provides a blueprint of how our Kafka Streams application processes data. It is important for Optimization, Debuting and Documenting
Step 2: Create Redis Sink Connector
As we have demonstrated in our provisos article, We will create Redis sink connector to sink data from the kafka stream output topic to Redis to get real time average customer spending.
-
Redis Sink connector
{
"name": "Average_Spending_RedisSinkConnector",
"config": {
"value.converter.schemas.enable": "false",
"name": "Average_Spending_RedisSinkConnector",
"connector.class": "com.redis.kafka.connect.RedisSinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"topics": "average-spending",
"redis.cluster": "false",
"redis.host": "redis",
"redis.password": "*****",
"redis.command": "JSONSET"
}
}
Here, we’ve defined our redis sink connector that reads data from average-spending and push it to Redis, We used String converter for key and json converter for value, as our data is JSON with no attached schema we have disabled schema validation "value.converter.schemas.enable: false" and we used JSONSET command to save data as json in Redis.
Now lunch the sink connector, and we will insert some test data in the Transaction table and make sure that the stream application is running :
INSERT INTO public.T_Transactions (id, transaction_ref_number, customer_id, account_id, transaction_amount,
transaction_type, created_at, updated_at)
VALUES (DEFAULT, 'ref-03'::varchar, 2::integer, 2::integer, 10::integer, 'Credit'::varchar, DEFAULT,Default);
INSERT INTO public.T_Transactions (id, transaction_ref_number, customer_id, account_id, transaction_amount,
transaction_type, created_at, updated_at)
VALUES (DEFAULT, 'ref-033'::varchar, 2::integer, 2::integer, 10::integer, 'Credit'::varchar, DEFAULT,Default);
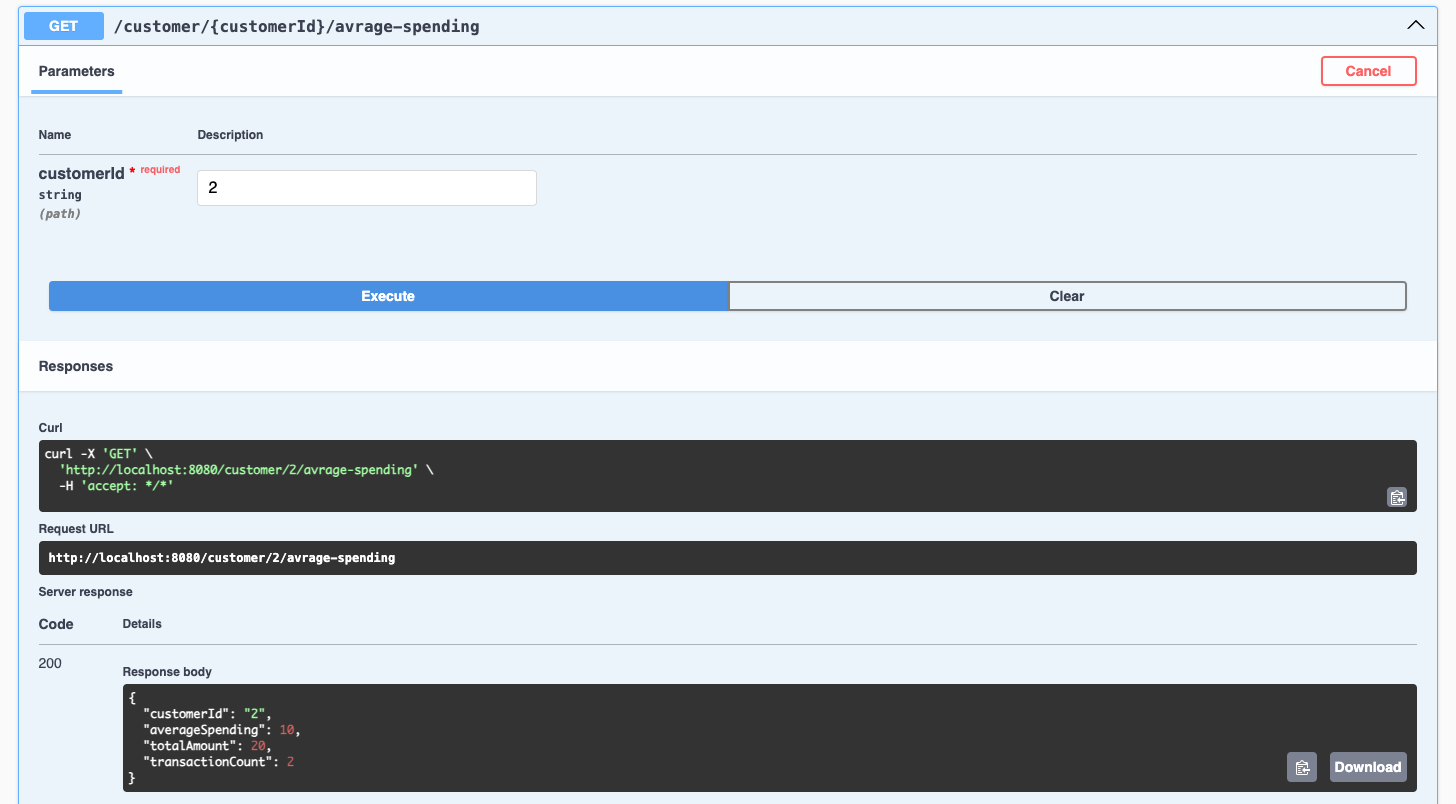
Here, we’ve insert new records to Transaction table for customer Id = 2 in redis you will found json document with key <topic_name>:<customer_id> and we will found that customer ID = 2 has 2 transactions with average spending = 10 , total transactions count = 2 and total transaction amount = 20
Step 3: Update Microservice to Read data from Redis
Now we have the data presented in our Redis , lets start updating our microservice to include a new api to get the average spending by customer Id .
We will create out Document Class that represent the Json Document in redis as following :
@Data
@RequiredArgsConstructor(staticName = "of")
@AllArgsConstructor(access = AccessLevel.PROTECTED)
@Document(value = "average-spending",indexName = "average-spendingIdx")
public class AverageSpending {
@Id
@Indexed
private String customerId;
private double averageSpending;
private double totalAmount;
private long transactionCount;
}Create Repository class :
@Repository
public interface AverageSpendingRepository extends RedisDocumentRepository<AverageSpending,String> {
}Update Customer Service by adding new method to get customer spending by customer Id:
public Optional<AverageSpending> getCustomerAverageSpending(String customerId){
return averageSpendingRepository.findById(customerId);
}And finally update our customer controller Class with new API :
@GetMapping("/{customerId}/avrage-spending")
public ResponseEntity<AverageSpending> getCustomerAverageSpending(@PathVariable String customerId) {
Optional<AverageSpending> averageSpending = customerService.getCustomerAverageSpending(customerId);
if(averageSpending.isPresent()) {
return ResponseEntity.ok(averageSpending.get());
}
return ResponseEntity.notFound().build();
}Lets Test Our new service with customer Id = 2
Summary
In this article, we demonstrated how to build a Kafka Streams application to calculate the average spending of customers using real-time transaction data.
The implementation covers:
-
Filtering and processing credit transactions.
-
Aggregating data with Kafka Streams to compute customer insights.
-
Storing results in Redis for efficient retrieval.
-
Exposing the processed data via a REST API for downstream applications.
This article highlights the seamless integration of Kafka Streams and Redis, showcasing how real-time analytics can enhance customer experience and drive business decisions.
Full implementation details are available in the GitHub repository for further customization:
-
data-preload updated code.